By
By
"Over the last few years, we have focused on helping clients improve business decision-making and risk management through better data management platforms and practices. That work has consistently centered on defining data more clearly, structuring it more effectively, and aligning it more closely to how the business actually operates. What is now becoming clear is that this same foundation is not just beneficial, it is a prerequisite for successful AI outcomes. In this article, we outline why data context sits at the center of this new age."
Introduction
Most organizations are investing heavily in AI. Many have modern data platforms; some have centralized data in warehouses and lakes; and all have access to powerful models. Yet many are not seeing meaningful outcomes at scale. This isn’t a model problem or a tooling problem; it’s a data problem. More precisely, it’s a lack of data context.
The Question Has Changed
For the last decade, the dominant question in data was simple: Does our data platform support analytics? Today, that question is no longer sufficient. It has been replaced by something more fundamental: Does our data support AI?
This is not a minor evolution; it is a structural shift. Analytics requires data to be structured, aggregated, and accessible, whereas AI requires data to be understood.
The Missing Layer: Data Context
|
Data context is the additional information that defines and describes your data. It captures the entities your data represents, the attributes that describe them, the relationships among them, the identifiers used across systems, and how those entities evolve. Together, these elements define the structure and meaning of your data, and this is where most organizations fall short. AI does not struggle with data volume; it struggles with data meaning. Data Context is the layer that gives data meaning, not just structure, and enables both humans and AI systems to interpret and use data consistently. |
What is Data Context?
|
Why AI Fails Without Context
AI systems are not just querying data; they are interpreting it. When context is missing, AI is forced into inference. It must infer what entities exist, guess how those entities relate, reconcile conflicting definitions, and interpret ambiguous fields. This introduces systemic risk into every output, resulting in inconsistent answers, fragile reasoning, and limited ability to scale across use cases.
When data context is present, this dynamic changes entirely. AI can operate with explicit structure, understand entities, navigate relationships, and reason across domains without guesswork. It stops inferring and starts reasoning.
Common Pitfalls & How to Solve
When working with clients who are trying to understand why their AI initiatives are not generating the outcomes they expect, we consistently see one or more of the following pitfalls.
The First Trap: No Common Data Layer
In many organizations, AI is connected directly to operational systems, each of which defines data differently. There is no shared structure, no consistent definitions, and no unified identity model. The result is fragmentation, where AI becomes dependent on a collection of disconnected sources, each with its own interpretation of the business. At that point, reliability is not just difficult; it is structurally constrained.
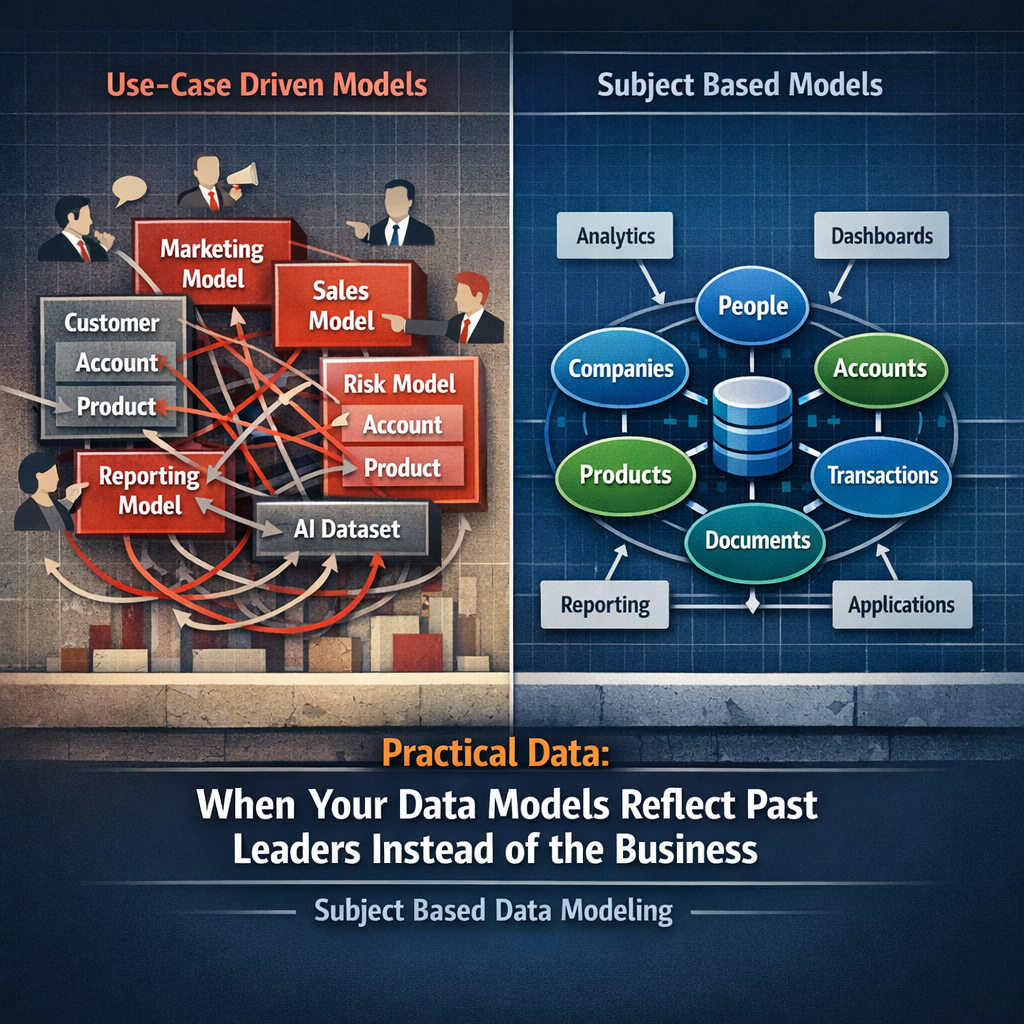
The Second Trap: The Two-Layer Model
More mature organizations centralize data into a warehouse and transform it into curated, business-ready datasets designed to answer specific questions and support defined analytical use cases. While this improves reporting, it introduces a different limitation: the data becomes shaped around predefined questions. That works for dashboards, but not for AI.
AI requires flexibility. It needs to explore, combine, and reason across data in ways that were not anticipated in advance. When data is modeled around use cases, that flexibility is lost.
The Third Trap: Reverse Engineering Meaning
A common assumption is: “We have all our data centralized, surely we can derive context from it.” In practice, this rarely works. A data warehouse captures transformations, aggregations, and reporting logic, but it does not fully capture true entity definitions, relationships between entities, lifecycle and state transitions, or business meaning.
As a result, teams attempt to reconstruct context after the fact, creating both gaps and inefficiencies. The same work gets done twice: first to build the platform, and again to rediscover what the data actually means.
Define Context First
| When working with organizations, we take a different approach. Many organizations start with technology design and individual use cases; we start with the data itself and focus on what the data represents.
We have previously written about our data-first approach and subject-based data modeling to simplify and automate data warehouse design. By focusing on data context first, the resulting platforms are inherently AI-ready, with data context already embedded. Data context is designed upfront and then used to drive everything else: data platform design, warehouse structure, schema automation, and AI system integration. This reverses the traditional model. The New Data Architecture:
|
 |
Model Around Real-World Subjects
At the core of this approach is subject-based data modeling, where data is organized around real-world entities such as people, companies, products, accounts, and transactions. Each subject is defined with attributes, identifiers, relationships, and lifecycle states. This ensures data is modeled based on what it is, not how it is used; a distinction that is critical for enabling AI to operate beyond predefined use cases.
Codifying Data Context
Definition alone is insufficient; data context must be codified in machine-readable data contracts, typically in JSON. When codified, data models become version-controlled and reusable across systems. This enables consistency, scalability, and alignment across the data ecosystem, while also making context directly consumable by AI systems.
The Missing Capability: A Centralized Data Design Authority
To sustain this at scale, organizations need a dedicated capability. A Data Design Authority is responsible for defining and maintaining data models, managing business definitions, governing identifiers, and maintaining relationships across domains. This is not passive governance; it is an active design function and the system of record for data context. Without it, context fragments over time.
Enabling AI Through Context
Once the data context is defined and codified, it can be exposed directly to AI systems. This is where the shift becomes operational. AI can access explicit definitions, understand relationships, and interpret data without inference. It no longer guesses; it operates on a defined structure.
Why This Approach Works
This approach creates four structural advantages: consistency (data is defined once and reused everywhere), scalability (new use cases do not require redesign), flexibility (AI can explore beyond predefined questions), and efficiency (teams eliminate duplicated effort).
Define Once. Use Everywhere
Most organizations still operate in a reactive model: build the data, then try to understand it. The more effective model is the opposite: define the data, then build systems that reflect that definition.
Final Thought
Most AI strategies focus on models, tooling, and infrastructure. But the real leverage point sits one layer above all of that, in how your data is defined. AI success is not determined by how much data you have; it is determined by how well your data is understood.
At M&A Operating System, this data-first focus is the foundation of our approach to AI. We have spent years building capabilities in data definitions and logical data models, and in automating master data management and modern data platforms. Today, that same foundation enables us to deliver true data context for AI.
Through our Data Design Authority capability, we help organizations define and codify their data models, automate and align their data platforms, and enable AI to leverage their data fully. If you are looking to move beyond fragmented data and unlock real AI outcomes, the starting point is not another tool; it is properly defining your data, once and for the long term.